Getting Started With Apache Spark
This blog post is a summary of my presentation on Apache Spark Overview with a basic Kafka streaming application. It includes some basic steps to create and deploy a simple Spark application. This is not a comprehensive tutorial, so for more information, please visit the Apache Spark website.
Prerequisite #
Apache Spark Overview #
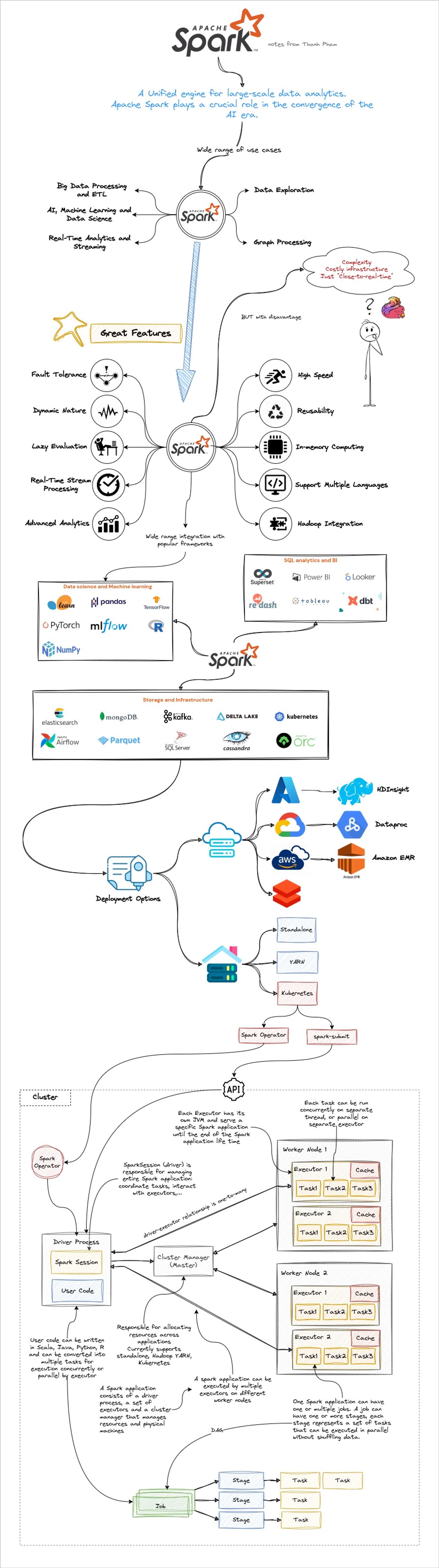
Build Spark Application #
Main.scala
import org.apache.spark.sql.SparkSession
object Main {
def main(args: Array[String]): Unit = {
val spark:SparkSession = SparkSession.builder()
.appName("hello-spark")
.getOrCreate()
import spark.implicits._
val kafkaOpts = Map[String, String](
"kafka.bootstrap.servers"-> "kafka:9092",
"subscribe"-> "test",
"kafka.sasl.mechanism"-> "PLAIN",
"kafka.security.protocol" -> "SASL_PLAINTEXT",
"kafka.sasl.jaas.config"-> """org.apache.kafka.common.security.plain.PlainLoginModule required username="user1" password="kk3gaqZRly";""",
)
val df = spark
.readStream
.format("kafka")
.options(kafkaOpts)
.load()
val ds = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
ds.writeStream
.format("console")
.outputMode("append")
.start()
.awaitTermination()
}
}
Note that in the above code we put the user/password of Kafka directly in the code which is just for simplicity & testing purpose. For production please store them in Vault or Secret instead.
build.sbt
ThisBuild / version := "0.1.0-SNAPSHOT"
ThisBuild / scalaVersion := "2.12.18"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.5.1"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.5.1"
libraryDependencies += "org.apache.spark" %% "spark-sql-kafka-0-10" % "3.5.1" % Test
Compile / run / mainClass := Some("Main")
lazy val root = (project in file("."))
.settings(
name := "hello-spark"
)
Dockerfile
ARG SCALA_VERSION=2.12
ARG ARG_JAR_NAME=hello-spark_2.12-0.1.0-SNAPSHOT.jar
ARG ARG_MAIN_CLASS=Main
FROM sbtscala/scala-sbt:graalvm-ce-22.3.3-b1-java17_1.9.9_2.12.18 as build
WORKDIR /app
COPY . .
RUN sbt package
FROM apache/spark:3.5.1-scala2.12-java17-ubuntu
ARG ARG_JAR_NAME
ARG ARG_MAIN_CLASS
ARG SCALA_VERSION
COPY --from=build /app/target/scala-${SCALA_VERSION}/${ARG_JAR_NAME} /app/work/application.jar
Build application Docker image
eval $(minikube -p minikube docker-env)
docker build -t hello-spark:latest .
Deploy Kafka #
helm install kafka oci://registry-1.docker.io/bitnamicharts/kafka
Notice the notes after you installed Kafka, it includes information for authenticate with Kafka cluster. Otherwise you can check the server.properties:
kubectl exec kafka-controller-0 -- cat /opt/bitnami/kafka/config/server.properties
Let run Kafka-client to create topic and test our Kafka cluster.
kubectl run kafka-client --rm -ti --image bitnami/kafka:3.6.1-debian-12-r12 -- bash
cd /opt/bitnami/kafka/bin
cat >> client.conf <<EOF
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="user1" password="kk3gaqZRly";
EOF
kafka-topics.sh --create --topic test --bootstrap-server kafka:9092 --command-config client.conf
kafka-console-producer.sh --topic test --request-required-acks all --bootstrap-server kafka:9092 --producer.config client.conf
kafka-console-consumer.sh --topic test --bootstrap-server kafka:9092 --consumer.config client.conf
Deployment #
Deploy Spark application to Kubernetes cluster require a ServiceAccount, hence we need to create it first:
kubectl create serviceaccount sparksubmit
kubectl create clusterrolebinding sparksubmit-role --clusterrole=edit --serviceaccount=default:sparksubmit --namespace=default
Deploy a Spark application to Kubernetes can be done by 2 ways:
- Using spark-submit
- Using Spark-operator
Deploy using spark-submit #
In this deployment mode, we submit the application using spark-submit from outside of the Kubernetes cluster. To install the spark-submit, you can download and setup the Apache Spark on your machine or pipeline:
wget https://www.apache.org/dyn/closer.lua/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz
tar -xzf spark-3.5.1-bin-hadoop3.tgz -C ~/bin
export PATH=$PATH:~/bin/spark-3.5.1-bin-hadoop3
export PATH=$PATH:~/bin/spark-3.5.1-bin-hadoop3/bin
export SPARK_HOME=~/bin/spark-3.5.1-bin-hadoop3
export HADOOP_HOME=~/bin/spark-3.5.1-bin-hadoop3
Note that for testing the Spark application locally, you also must install Java (17) and Scala (2.12) on your local machine.
After installed spark-submit, go ahead to submit the Spark application:
spark-submit \
--master k8s://https://127.0.0.1:32769 \
--deploy-mode cluster \
--name hello-spark \
--class Main \
--conf spark.kubernetes.namespace=default \
--conf spark.kubernetes.container.image=hello-spark:latest \
--packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1 \
--conf spark.driver.extraJavaOptions="-Divy.cache.dir=/tmp -Divy.home=/tmp" \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=sparksubmit \
--conf spark.kubernetes.authenticate.submission.caCertFile=~/.minikube/ca.crt \
local:///app/work/application.jar
Notes:
- Run
kubectl cluster-info to get the URL of your K8S cluster. - Replace the
caCertFile to your certificate file. If relative path doesn't work, change to absolute path.
After deployed, you would see the driver and executors got deployed in your K8S:
kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-spark-3605288e2b93f981-exec-1 1/1 Running 0 10s
hello-spark-3605288e2b93f981-exec-2 1/1 Running 0 10s
hello-spark-6da76b8e2b92dd56-driver 1/1 Running 0 82s
kafka-controller-0 1/1 Running 1 (12m ago) 14h
kafka-controller-1 1/1 Running 1 (12m ago) 14h
kafka-controller-2 1/1 Running 1 (12m ago) 14h
Once the driver and the executors are up and running, you can start the Spark UI to see the application detail as well as start sending some events to Kafka and check for the output from log of the driver.
kubectl port-forward hello-spark-6da76b8e2b92dd56-driver 4040:4040
If you would like to kill the application, just run spark-submit with -kill option:
spark-submit --kill hello-spark-d5358c8e1cd2e8b0-driver --master k8s://https://127.0.0.1:32769
Deploy using Spark-Operator #
Deploy Spark application using Spark operator is recommended for production. In this deployment model, we will install spark-operator inside K8S cluster, spark-operator will listen on any application deployed to the K8S with application kind as SparkApplication and will help us to submit Spark application to the K8S for us.
You can read more detail on using spark-operator at their user-guide
Install spark-operator:
helm repo add spark-operator https://kubeflow.github.io/spark-operator
helm install spark-operator spark-operator/spark-operator --namespace spark-operator --create-namespace --set enableWebhook=true
Note that the option --set enableWebhook=true must be enabled if you would like to use some certain Spark operator features such as setting env or GPU for driver and executor. See more here
Check for the deployment status:
kubectl get pod -n spark-operator
NAME READY STATUS RESTARTS AGE
spark-operator-675d97df85-c2b9g 1/1 Running 2 (46m ago) 14h
Create application deployment file spark-application.yaml
apiVersion: sparkoperator.k8s.io/v1beta2
kind: SparkApplication
metadata:
name: hello-spark
namespace: default
spec:
type: Scala
sparkVersion: 3.5.1
mode: cluster
image: hello-spark:latest
mainClass: Main
mainApplicationFile: local:///app/work/application.jar
deps:
packages:
- org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1
sparkConf:
"spark.driver.extraJavaOptions": "-Divy.cache.dir=/tmp -Divy.home=/tmp"
driver:
memory: 512m
labels:
version: 3.5.1
serviceAccount: sparksubmit
executor:
memory: 512m
instances: 3
labels:
version: 3.5.1
Deploy it to the cluster
kubectl apply -f spark-application.yaml
Wait for sometime for spark-operator to detect and submit the application and then you can start testing the application:
kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-spark-driver 1/1 Running 0 54s
hello-spark-efd4f18e2bb34946-exec-1 1/1 Running 0 4s
hello-spark-efd4f18e2bb34946-exec-2 1/1 Running 0 4s
hello-spark-efd4f18e2bb34946-exec-3 1/1 Running 0 4s
kafka-controller-0 1/1 Running 1 (46m ago) 14h
kafka-controller-1 1/1 Running 1 (46m ago) 14h
kafka-controller-2 1/1 Running 1 (46m ago) 14h
At this step, we've done for the very basic Spark application from development to deployment. But as mentioned earlier, we should not put username and password directly in the code but should store them in Vault or Secret. By applying spark-operator, we can easily do this using env config of the operator(but remember to enable option enableWebhook=true when installing spark-operator)
Let update the code and the deployment file as below:
Main.scala
import org.apache.spark.sql.SparkSession
object Main {
def main(args: Array[String]): Unit = {
val spark:SparkSession = SparkSession.builder()
.appName("hello-spark")
.getOrCreate()
import spark.implicits._
val user = sys.env.getOrElse("KAFKA_USER", "user1")
val pass = sys.env.getOrElse("KAFKA_PASS", "xxx")
val kafkaOpts = Map[String, String](
"kafka.bootstrap.servers"-> "kafka:9092",
"subscribe"-> "test",
"kafka.sasl.mechanism"-> "PLAIN",
"kafka.security.protocol" -> "SASL_PLAINTEXT",
"kafka.sasl.jaas.config"-> s"""org.apache.kafka.common.security.plain.PlainLoginModule required username="$user" password="$pass";""",
)
val df = spark
.readStream
.format("kafka")
.options(kafkaOpts)
.load()
val ds = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
ds.writeStream
.format("console")
.outputMode("append")
.start()
.awaitTermination()
}
}
spark-application.yaml
apiVersion: sparkoperator.k8s.io/v1beta2
kind: SparkApplication
metadata:
name: hello-spark
namespace: default
spec:
type: Scala
sparkVersion: 3.5.1
mode: cluster
image: hello-spark:latest
mainClass: Main
mainApplicationFile: local:///app/work/application.jar
deps:
packages:
- org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1
sparkConf:
"spark.driver.extraJavaOptions": "-Divy.cache.dir=/tmp -Divy.home=/tmp"
driver:
memory: 512m
labels:
version: 3.5.1
serviceAccount: sparksubmit
env:
- name: KAFKA_USER
value: "user1"
- name: KAFKA_PASS
valueFrom:
secretKeyRef:
name: kafka-user-passwords
key: client-passwords
executor:
memory: 512m
instances: 3
labels:
version: 3.5.1
Note that the secret kafka-user-passwords is the secret that created by Binami Kafka helm chart above. If you use another type of chart please double check the name or you can also create a secret yourself and update the deployment file accordingly.